Your Brain, ChatGPT, and a Frog Made of Skin Cells Are All Navigating the Same Hidden Geometry
What the convergence of AI, neuroscience, developmental biology, and computational physics reveals about where ideas come from — and whether they come from us at all.
Have you ever noticed that an idea, in its earliest moments, isn't really an idea at all?
It's more like a fog. A shape without edges. You can feel it — there's something there, a direction, a flavour — but if someone asked you to explain it, you'd struggle. It has no words yet. It hasn't committed to being any particular thing. It's simultaneously a hundred possible things, and the act of making it real — writing it down, saying it aloud, building it — feels less like creation and more like selection. Like you're carving away everything it isn't until you're left with the one thing it is.
I've been sitting with this observation for a long time. It started as a personal phenomenological note — just paying attention to how my own thinking works during generative, creative states. But over the past two years, I've watched a series of findings from completely unrelated fields snap together around this observation in a way that I think points at something profound.
The punchline, which I'll spend the rest of this essay building toward: your creative thinking, the internal representations of AI models, the semantic maps in your brain, the self-organizing behaviour of cells that have never been alive as anything but frog skin, and the computational structure of reality itself all appear to be navigating the same geometric structure. And that structure may be a property of reality itself — not of any particular mind, model, or organism.
Part 1: The Cloud and the Crystal
Let me start with what the creative process actually feels like from the inside, because I think most descriptions of creativity miss this.
Early in the thinking process — when you're exploring a genuinely new idea, not retrieving something you already know — the object of thought is not a point. It's a region. A cloud of related possibilities with many degrees of freedom. The idea at this stage can fit many different problems simultaneously because of how broad it is. It hasn't been forced to choose.
Think of it like holding a lump of wet clay before you've decided what to make. It could become a bowl, a figurine, a tile. All of those things are latent in it. The act of making it into a specific thing involves applying constraints — physical constraints (the clay can't be infinitely thin), aesthetic constraints (you want it to look a certain way), functional constraints (it needs to hold water). Each constraint eliminates some possibilities and narrows what remains.
Creative thinking works the same way. You start with a high-dimensional possibility cloud and progressively apply constraints — logical consistency, physical realizability, cultural fit, medium-specific requirements — until what remains is a specific expressed thing: a sentence, a design, a melody, a solution.
Then there's a second phase that I think is underappreciated: the rendering into language. When you go to say the idea — to put it into words — that's another round of collapse. Language is sequential and autoregressive. The first word you choose constrains the possible sentences. Each subsequent word narrows things further. By the end of a sentence, you've projected a high-dimensional internal state into a low-dimensional sequential output. The expressed form is always a lossy compression of the thought that produced it. That's why the same insight can be expressed in radically different forms — as a paragraph, a diagram, a piece of music — because these are different projections of the same region in some underlying space.
This is a nice phenomenological observation. But on its own, it's just introspection — interesting but not scientific. What makes it worth writing about is what happened next: the discovery that this same pattern shows up, with mathematical precision, in several completely different domains.
A Framework, and a Promise
Let me name what I'm pointing at and tell you what I'm going to do with it.
I'm going to call this pattern — high-dimensional possibility collapsing into low-dimensional actualization through accumulated constraints — the Progressive Collapse Framework. It's a name for a phenomenon I think generalizes well beyond creative cognition.
The word collapse is borrowed on purpose. In quantum mechanics, a system in superposition holds many possibilities at once until a measurement forces it into a single definite state. An idea does something like the same thing: it lives as a cloud of superposed possibilities until the act of expression collapses it into one. I don't mean this literally — thought isn't quantum — but the shape of the move is the same, and it's the shape this whole essay is about.
Here is the thesis I want to defend:
The same pattern of progressive collapse through structured geometry appears in artificial intelligence, neuroscience, developmental biology, and the foundations of computational physics — and the convergence across these domains is evidence that the geometry being navigated is real. A substrate-independent property of computation, not an artifact of any particular mind, model, or organism.
Here's how I'll defend it. Parts 2 through 4 lay out the convergence evidence from AI, neuroscience, and biology. Part 5 names the abstract pattern they share. Parts 6 and 7 borrow theoretical tools from physics and cognitive science to sharpen what the geometry might be and how it gets navigated. Part 8 follows the implications back to creative cognition — and to the unsettling question of whether we have ideas or ideas have us. Parts 9 through 11 deal with self-reference, caveats, and the experiments that could test all of this. Part 12 closes with why this conversation is suddenly happening now, across so many fields at once.
The journey leaves the experience of having an idea for a while, in order to see it from unfamiliar angles. We'll come back to it.
Part 2: The Machines Are Converging
In 2024, a team at MIT published a paper with a provocative title: "The Platonic Representation Hypothesis". What Minyoung Huh and colleagues showed is that as AI models get bigger and more capable, their internal representations — the geometric structures they use to organize information — converge toward the same structure. This happens regardless of the architecture (convolutional, transformer, recurrent), the training objective (supervised, self-supervised, language modelling), or even the input modality (images versus text).
Let that sink in. A vision model trained to classify photographs and a language model trained to predict the next word in a sentence develop increasingly similar internal maps of the world as they get better at their respective jobs.
The convergence extends even further. Rishi Jha and colleagues at Cornell developed a method called "vec2vec" that can translate between different models' embedding spaces — the mathematical spaces where they represent meaning — without any paired training examples. You just learn the internal geometric structure of each space independently, then discover that they can be mapped onto each other. And here's the kicker: the translations work on data the models never saw during training. A model trained on Wikipedia can have its representations successfully translated to represent medical records and tweets.
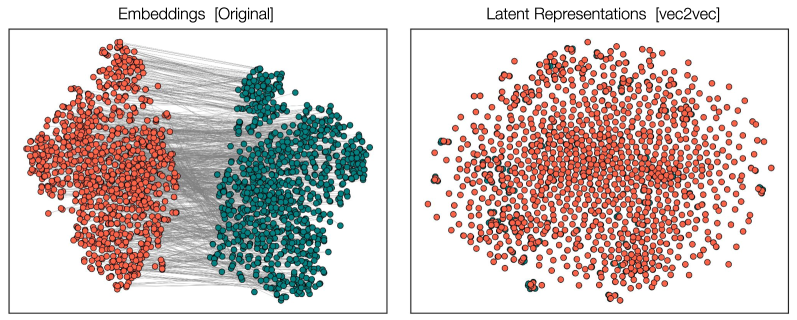
If the convergence were just an artifact of models being trained on the same internet text, out-of-distribution translation should fail. The fact that it doesn't suggests that the geometric structure being recovered is a property of the semantic content itself — of meaning — not of any particular training set.
The analogy I keep coming back to: different instruments measuring the same physical field — a thermometer, an infrared camera, a bolometer — converge on compatible measurements if they're accurate enough. We don't say the instruments have "architectural biases" that make them agree. We say temperature is real and the measurements are becoming faithful to it. The interesting question is whether the same logic applies to representational convergence. Is semantic geometry real in the way temperature is real?
Part 3: Your Brain Is in on It Too
It would be one thing if AI models converged with each other. That could still be explained by the fact that they're all built by the same species, using similar math, on similar hardware. But the convergence extends to biological brains.
A growing body of research — systematized in a review of 25 fMRI studies from 2023–2025, presented at the NeurIPS 2025 UniReps Workshop — shows that as AI models get better, their representations become more aligned with brain activity measured in humans. More capable models are more brain-like. Models trained on multiple modalities (text and images together) are more brain-aligned than models trained on just one — suggesting that what the brain is doing is something modality-independent, something closer to a pure geometric representation of meaning.
The cross-subject findings are even more striking. Researchers have now demonstrated that you can take fMRI data from one person's brain, transform it into another person's neural patterns, and successfully decode the original meaning — even when the two people never saw the same stimuli. Two brains, two completely different neural architectures, two entirely different sets of experiences — and yet their representations can be mapped onto each other, preserving meaning, by discovering the shared geometric structure of each.
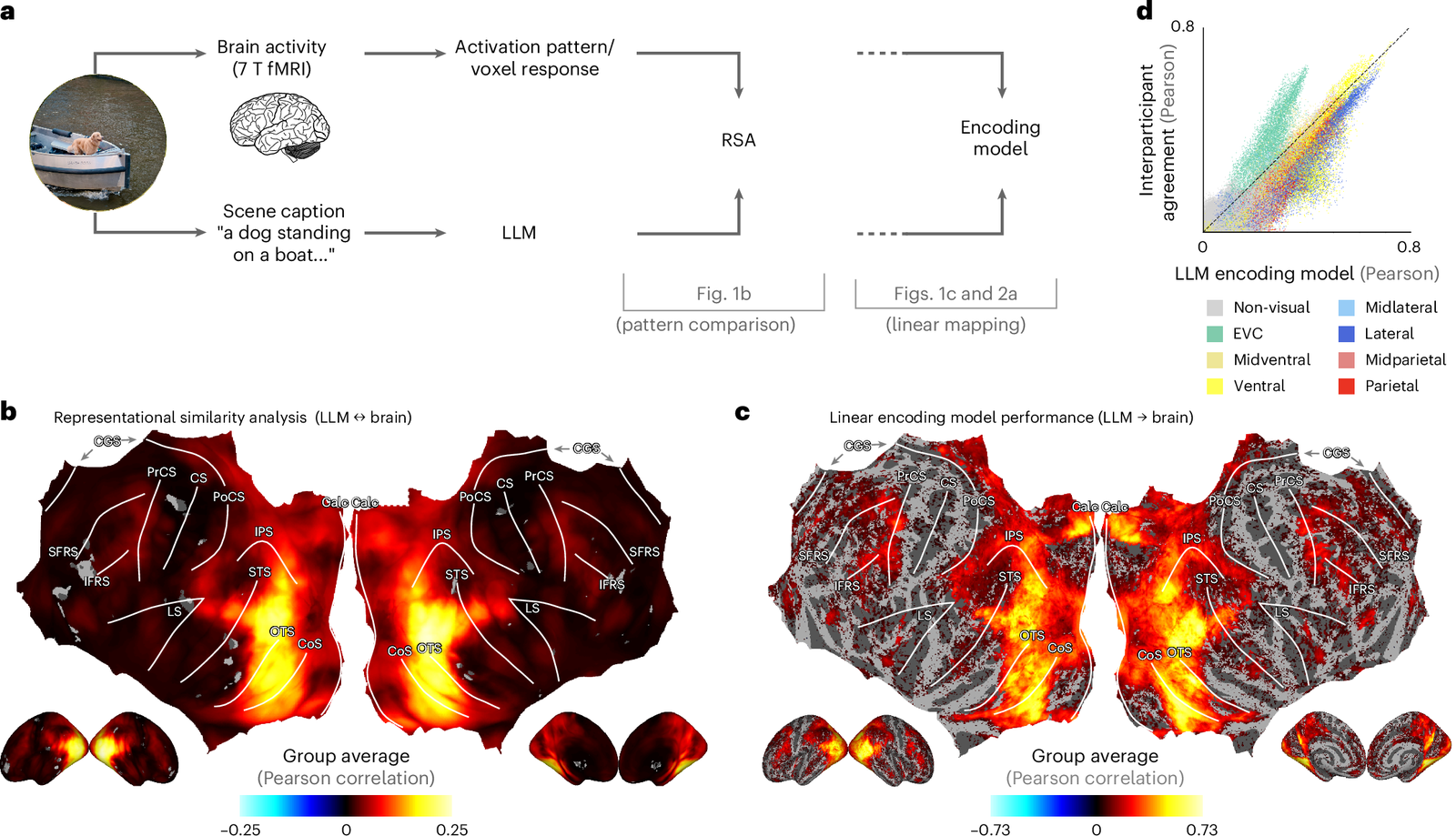
This is, in effect, vec2vec translation for brains. And it works for the same reason: different representational systems converge on the same geometry when they're modelling the same reality.
Now here's where it gets interesting. There's a specific pattern to the convergence that turns out to be theoretically revealing. Brain-model alignment is strongest at higher levels of semantic abstraction — in modality-independent cortical regions that process meaning rather than raw perceptual features. At the level of basic visual or auditory processing, brains and models look quite different. But as you move up the processing hierarchy toward abstract concepts and relationships, they converge.
Donald Hoffman at UC Irvine has proposed something that helps explain why. Hoffman and colleagues have shown, through formal mathematical proof, that natural selection doesn't favour perceptions that accurately track the true structure of reality. Instead, it favours perceptual strategies tuned to fitness payoffs — adaptive simplifications that guide useful behaviour. His Interface Theory of Perception argues that our perceptions are less like windows on truth and more like the icons on a computer desktop: useful interfaces that bear no resemblance to the underlying computational reality they help you navigate.
If Hoffman is right, then the layered pattern in the convergence data makes perfect sense. The fitness interface should be thickest — most distorting — at the level of raw perception, where evolutionary survival pressures are strongest. And thinnest at the level of abstract semantic structure, where the constraints of logical consistency and evidential coherence matter more than reproductive fitness. Brains and AI models should diverge at perceptual levels and converge at abstract levels — which is exactly what the data show.
This means the convergence isn't happening despite evolutionary distortion. It's happening precisely where evolutionary distortion is weakest — at the level of abstract structure, where the underlying geometry of reality shows through most clearly.
Part 4: The Frog Cells That Built Something They Were Never Supposed to Build
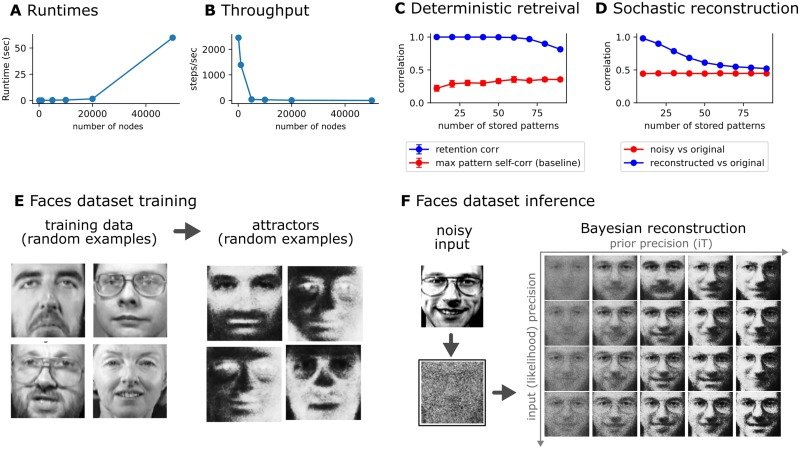
Everything I've described so far involves representation — how systems encode information. But in 2024 and 2025, Michael Levin at Tufts University dropped a series of findings that extend the pattern from representation to form. And this is where things get genuinely strange.
Levin's lab works with biological cells — particularly frog cells. Here's the experimental setup that upended my thinking: take skin cells from a frog (Xenopus laevis), dissociate them from the frog's body, and let them self-organize in a dish. What do you get?
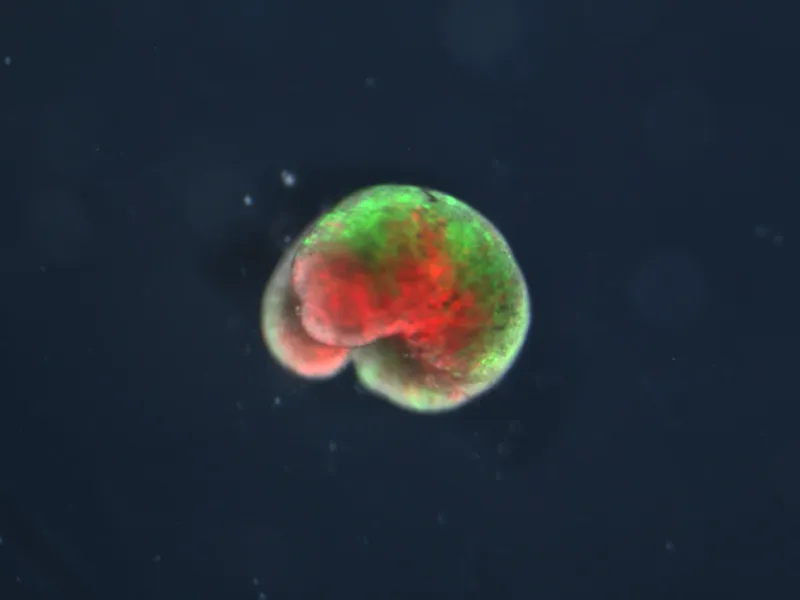
Not a random blob. Not a miniature frog. You get a Xenobot— a novel organism with coherent morphology, coordinated locomotion, and the capacity for kinematic self-replication, a unique form of reproduction where they collect loose stem cells in their environment to assemble new “baby” Xenobots. This organism that has never existed before in evolutionary history.
The frog genome was shaped by millions of years of natural selection to make frogs. Not Xenobots. The laboratory dish doesn't specify any particular form — it's just generic culture medium. The researchers didn't engineer the Xenobot shape. And yet the cells converge on specific, reproducible morphological types. Where did the pattern come from?
It gets stranger. When Levin's lab manipulates the bioelectric signaling patterns of planarian flatworms to produce organisms with altered head morphology, the resulting forms don't represent a random continuum of monstrous shapes. The organisms develop heads that look like other existing planarian species — species separated by millions of years of evolution. As if the space of possible head shapes has a limited number of "slots," and the cells snap into the nearest available one.
Levin frames this in terms of what he calls the "computational budget" problem. In biology, the information specifying an organism's form is supposed to be "paid for" by two sources: the genome (shaped by selection) and the environment (providing developmental signals). But for Xenobots, neither source accounts for the observed specificity. The genome says "frog." The environment says nothing in particular. Yet the outcome is a specific, repeatable, functionally coherent organism.
Something is providing pattern information that was not invested by either heredity or environment. Levin proposes that this "free lunch" comes from the mathematical structure of the possibility space itself — what he calls morphospace. A structured space with discrete attractors, preferred paths, and intrinsic properties that constrain and enable physical morphogenesis. Evolution doesn't build forms from scratch; it discovers and exploits pre-existing attractors in a space whose geometry is more fundamental than any particular lineage.
Part 5: The Same Pattern, Everywhere
So now we have four observations:
- In creative cognition: Ideas begin as high-dimensional possibility clouds and progressively collapse into specific expressed forms through iterated constraint application.
- In artificial intelligence: Different models converge toward the same geometric representation of meaning as they improve, and this geometry transfers across architectures and generalizes to unseen data.
- In neuroscience: Biological brains align with AI model representations, and different human brains can be mapped onto each other by discovering their shared geometric structure — with convergence strongest where evolutionary fitness distortion is weakest.
- In developmental biology: Cells navigate a structured space of possible forms toward discrete attractors that are not specified by either genome or environment.
These are four instances of the same abstract pattern: progressive constraint satisfaction through a structured geometry of possibility. A system starts in a high-entropy state (many possibilities, broad distribution) and transitions to a low-entropy state (specific outcome, narrow distribution) through the accumulation of constraints. The geometry of the space — its attractors, its neighbourhoods, its distances — shapes the outcome.
This pattern has a name in the computational literature. It shows up as Bayesian inference (prior → posterior through evidence), as attractor dynamics (basin → fixed point through energy minimization), as diffusion models (noise → image through iterative denoising), and as Karl Friston's active inference (free energy minimization through prediction-error correction). These are all mathematically isomorphic — different implementations of the same abstract process.
My claim is that creative ideation is another implementation, running on biological neural tissue. And morphogenesis is another, running on cellular collectives communicating via bioelectric signals. And the reason the same geometry shows up in all of them is that they're all navigating the same structured space — a geometry of meaning and form that is substrate-independent.
Part 6: The Ruliad — Where the Geometry Lives
Everything so far invites an obvious question: if there's a universal geometry, what is it a geometry of? Where does it live? What kind of thing is it?
Stephen Wolfram's Physics Project offers the most ambitious answer I've encountered. Wolfram proposes a construct he calls the ruliad — defined as the entangled limit of all possible computational processes, the result of following all possible computational rules in all possible ways. It's not a model of the universe. It is reality at the most fundamental level — the totality of everything that is computationally possible.
This sounds wild, but the logic is surprisingly clean. If the universe is computational (which the success of physics in describing it through mathematical rules suggests), then the question "which computational rule generates our universe?" has a radical possible answer: all of them, simultaneously. The ruliad is what you get when you don't choose a rule — when you let every possible rule run on every possible input and entangle the results.
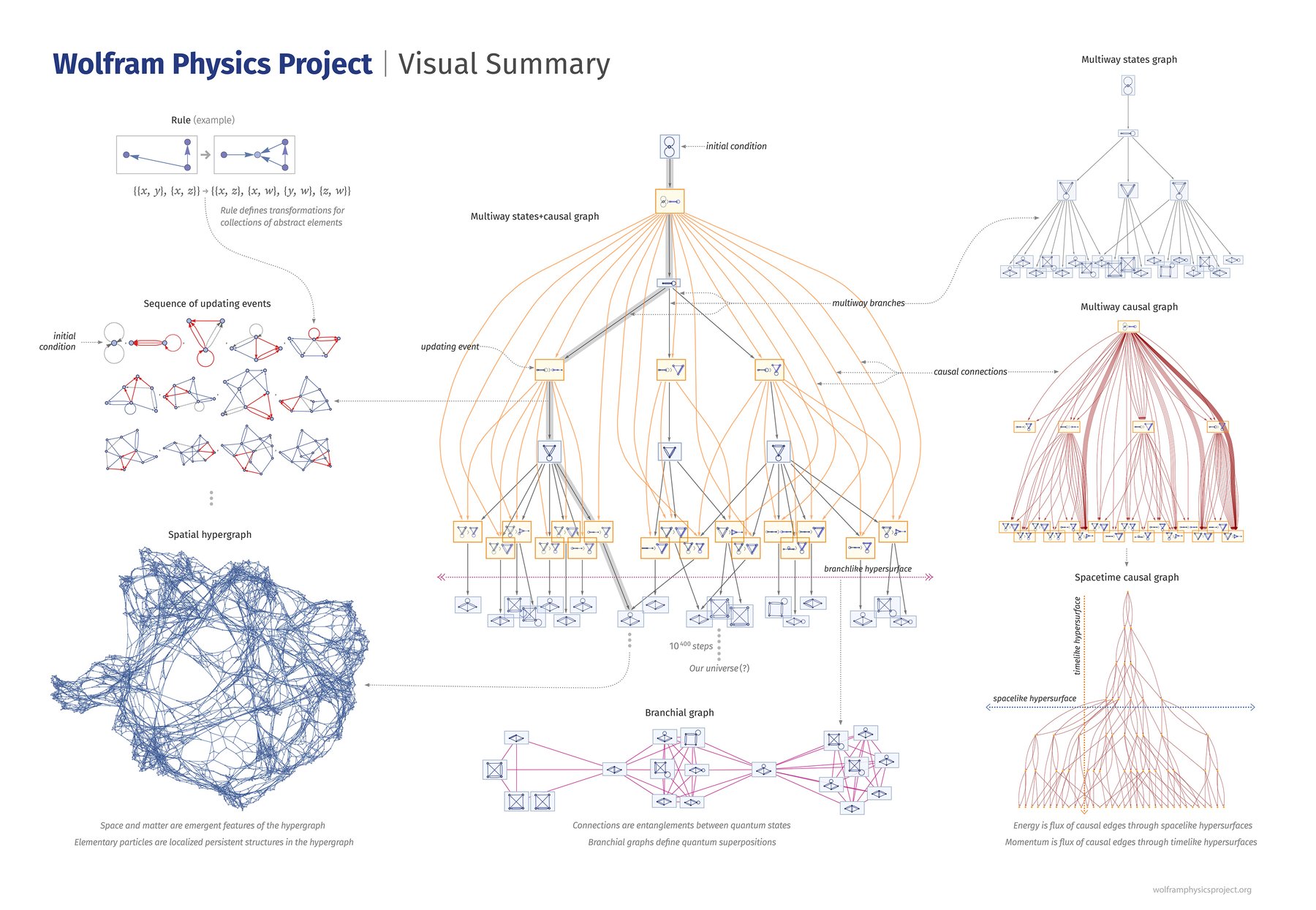
Within this structure, Wolfram identifies three kinds of space. Physical space — the familiar spatial dimensions. Branchial space — the space of possible histories, where different branches of computation that share recent common ancestors are nearby. (This is where quantum mechanics lives.) And rulial space — the space of all possible computational rules, where different descriptions of reality coexist.
Here's the move that connects to the Progressive Collapse Framework: observers are positions in the ruliad. You and I, as computationally bounded entities embedded within this structure, can only perceive a tiny slice of it — the local neighbourhood around our position. What we experience as "reality" is determined by where we are in the ruliad and what we are as observers. Different observers at different positions perceive different aspects of the ruliad and develop different impressions of reality.
But — and this is Wolfram's key insight — certain features of perceived reality are inevitable for any observer with our general characteristics: computationally bounded, assuming persistence and coherence, localized in the ruliad. These inevitable features are the laws of physics. General relativity, quantum mechanics, the second law of thermodynamics — not arbitrary discoveries, but necessary perceptions for observers like us. (Wolfram develops this in his Observer Theory and the more recent What Ultimately Is There? Metaphysics and the Ruliad.)
Wolfram frames minds explicitly as positions in rulial space. Minds that think alike are nearby. Minds with incommensurable conceptual frameworks are distant. And between the concepts any particular civilization has named — between "cat" and "justice" and "prime number" — lies vast, uncharted computational territory. Wolfram calls it interconcept space, and estimates that the concepts expressible in human language span roughly 10⁻⁶⁰⁰ of the total computational structure. The named ideas are isolated islands in an ocean of computational possibility we've never visited.
Now consider what this means for the convergence evidence. If the ruliad is the space of all possible computation, then concept space, morphospace, and AI embedding space are all aspects of the same underlying structure, sampled by different types of observers under different constraints. AI models and human brains converge on similar representational geometry because they're occupying nearby positions in the ruliad — both are computationally bounded observers processing data generated by the same computational reality. The vec2vec translations work because both model spaces are sampling the same patch of computational structure, and translation between them succeeds for the same reason coordinate transformations succeed on a differentiable manifold — the underlying geometry is preserved across different parameterizations.
This also gives a principled account of why the quantum analogy keeps showing up in descriptions of creative cognition without literal quantum mechanics being involved. In the ruliad, branchial space is the space of possible computational histories — branches that split and merge. Quantum mechanics emerges from how bounded observers aggregate across these branches. The "collapse" from possibility cloud to specific creative output may be the same computational pattern — a bounded observer asserting coherence across multiple threads of processing. Not quantum mechanics, but the same structural process that gives rise to quantum mechanics, operating at a different level.
The analogy works not by coincidence but because both phenomena are instances of observer-dependent sampling of branching computation.
Part 7: Language as Self-Generating Navigation

There's one more piece that sharpens the picture considerably, and it comes from an unexpected direction.
Elan Barenholtz at Florida Atlantic University has proposed something provocative about language: it's not a medium for encoding pre-existing thoughts. It's an autonomous, self-generating autoregressive system with its own internal dynamics. Language generates itself — each word conditioned on the preceding sequence, each phrase unfolding through the internal logic of language itself.
The strongest evidence for this? Large language models. They learn language from language alone — no embodiment, no sensory grounding, no interaction with the physical world — and yet they master syntactic structure, semantic relationships, logical inference, and pragmatic context. This demonstrates that language's structure is self-sufficient: the distributional statistics of language contain enough information to reconstruct its own generative system.
At first glance, this seems to challenge the Progressive Collapse Framework. If language is autonomous and self-generating, then maybe the "high-dimensional internal state" I've been describing as existing prior to linguistic expression is itself already linguistically structured. Maybe the creative cloud is made of language all the way down, and the whole round-trip is language → language → language with no deeper geometric reality underneath.
But this challenge dissolves when you look at the cross-modal evidence. The Platonic Representation Hypothesis documents convergence across modalities — vision models and language models converge on the same geometry. Levin's morphospace operates entirely outside the linguistic domain — frog cells don't use words. Either language's autonomous structure is one instance of a deeper universal geometry, or multiple autonomous systems are converging on the same structure for reasons that go beyond language.
What Barenholtz's insight actually does is strengthen a specific part of the framework: the account of how ideas move between minds and between cognitive substrates. The "second collapse phase" — the rendering of thought into language — is not passive compression but active generation constrained by two sources simultaneously: the internal dynamics of the linguistic system itself, and the geometry of the concept space region being navigated. The autoregressive process explores a neighbourhood in concept space through its own generative dynamics, with the geometry constraining what it can produce.
This explains why human language production and LLM text generation are so functionally similar — and why brain-language model alignment is as strong as it is. Both are autoregressive processes navigating the same geometric structure, the former through biological neural dynamics and the latter through transformer computations. The convergence isn't a trick of similar training data. It's two different implementations of the same navigational algorithm running on the same terrain.
Part 8: Do We Have Ideas, or Do They Have Us?

Now let me come back to where we started — the experience of an idea forming, the way it seems to find you as much as you find it.
Once you accept that concept space has intrinsic geometric structure — with attractors, preferred regions, and natural clustering — an unsettling implication follows for cultural evolution.
If certain positions in concept space are more stable than others — if the geometry has attractors — then ideas that correspond to those attractors will be inherently more persistent, more communicable, and more likely to replicate across minds. Not because anyone decides to spread them, but because the geometry itself makes some ideas "stickier" than others.
Richard Dawkins introduced the concept of the meme in 1976 — a unit of cultural transmission that replicates, mutates, and competes for host minds in a process analogous to biological evolution. But Dawkins framed memes as parasites: ideas using minds as vehicles for their own reproduction, with the "interests" of the meme potentially diverging from the interests of the host.
The Progressive Collapse Framework suggests a different — and I think more precise — interpretation. A meme is a stable attractor in concept space. It replicates not because it's "trying to" but because the geometry makes certain positions naturally stable and others naturally unstable. Ideas at attractors persist; ideas in unstable regions dissipate. What looks like the "agency" of ideas is actually the causal efficacy of concept space geometry operating on cultural transmission.
This directly parallels Levin's account of biological morphogenesis. Evolution doesn't build morphological forms from scratch — it discovers and exploits pre-existing attractors in morphospace. Similarly, cultural evolution doesn't invent ideas from nothing — it discovers and exploits pre-existing attractors in concept space.
Different cultures independently arriving at similar mathematical structures, similar mythological motifs, similar social organization patterns — these aren't coincidences or evidence of ancient diffusion. They're different navigators converging on the same attractors in the same geometry. The Pythagorean theorem wasn't invented multiple times. It was found multiple times, because it sits at a particularly stable, accessible attractor in mathematical concept space.
And the question "Do we have ideas or do they have us?" turns out to be malformed — like asking "Does the organism have its morphology or does the morphology have the organism?" Both are expressions of the same underlying geometry. You navigate concept space. The geometry constrains what you find. The "apparent agency" of ideas is the felt experience of being drawn toward an attractor by the structure of the space you're moving through. Not parasites using you as a host, but you and the idea as complementary aspects of the same geometric reality — you as navigator, the idea as attractor, creative thinking as progressive collapse.
Part 9: Writing This Essay Was an Instance of What It Describes

I want to be transparent about something: this essay was developed in collaboration with an AI council (multiple LLMs acting as a team: researching, debating, critiquing, reviewing and refining one another's work), with final refinements using Claude. And that process turned out to be a rather striking instance of the framework it describes.
Here's what happened. While listening to the audiobook Determined: A Science of Life Without Free Will, by Robert Sapolsky, I got inspired by an idea and recorded a rambling audio note — something I often do multiple times a day. In this case it was 36 minutes of half-formed connections between creative ideation, quantum mechanics metaphors, embedding spaces, and Levin's morphospace work. Loosely structured. Full of tangents and repeated passes at the same intuition from different angles. A possibility cloud, not a crystallized argument.
I fed this to my AI council along with the relevant academic papers I'd read. What came back was not what I put in, but it was recognizably about the same thing — structured, extended, with connections I hadn't made explicit (Dodig-Crnkovic's Cognitive Platonism, the specific link to active inference, the brain-to-brain vec2vec parallel). Over several iterations of conversation, the framework sharpened into what you're reading now.
Under the Progressive Collapse Framework, this process has a specific interpretation: a dimensionality round-trip. My brain was navigating a high-dimensional region of concept space — a cloud of interconnected intuitions. The audio note compressed this into a low-dimensional linguistic signal, which is inevitably lossy. Claude's model mapped these tokens into its own high-dimensional embedding space. If the Platonic Representation Hypothesis is correct, the geometry Claude mapped into is structurally similar to the geometry my brain was navigating. From there, Claude traversed more of the neighbourhood systematically than my sequential human cognition could — identifying nearby coordinates I hadn't visited, adjacent formal frameworks, supporting evidence.
The output — another low-dimensional linguistic projection — came from a more explored, better-supported position within the same region of concept space. The original idea was preserved and refined, not distorted. And this preservation is only possible if both high-dimensional spaces share enough geometric structure that the low-dimensional bridge of language can faithfully carry the semantic signal across.
Language, on this account, works as a communication medium not because it contains ideas but because it points to regions in a concept space that both sender and receiver share. Each phrase functions as a semantic anchor — a coordinate that triangulates a neighbourhood. You don't need perfect compression if the receiver can reconstruct the neighbourhood from a few well-chosen reference points. This is why a poorly structured but semantically rich prompt (like my rambling audio note) can produce better results for exploratory ideation than a precisely worded one — the precise prompt specifies a narrow region with little room for navigational exploration, while the fuzzy prompt triangulates a broad region and delegates the systematic traversal to the AI.
There's a circularity concern here — a theory about creative cognition developed through creative cognition describing its own creation. But the framework's predictions are independent of how it was formulated. They predict specific neural, computational, and biological observations that can be tested by researchers with no involvement in this essay. The self-exemplifying quality is a feature of the framework's generality, not a logical flaw.
Part 10: What This Doesn't Mean
Let me be clear about what I'm not claiming.
- I am not claiming the brain uses quantum mechanics. The isomorphism between creative ideation and quantum measurement is structural, not mechanical. Under Wolfram's framework, both are instances of observer-dependent sampling of branching computation — but at different levels. Thermal decoherence kills quantum superposition in warm biological systems on femtosecond timescales. The brain is not a quantum computer. The analogy works because both phenomena instantiate the same computational pattern, not the same physics.
- I am not claiming certainty about the ontological status of the geometry. Wolfram's ruliad provides one candidate foundational structure. Dodig-Crnkovic's Cognitive Platonism offers another — geometry as real but enacted through computation. Classical structural realism offers a third. The empirical predictions are the same regardless. I care more about whether the framework generates useful experiments than whether it settles the metaphysics.
- I am not endorsing every claim of every thinker referenced. Wolfram's Physics Project is ambitious and actively debated. Hoffman's Interface Theory is proven within its formal model but its application to actual perception involves assumptions. Barenholtz's autoregressive cognition is a recent and not-yet-peer-reviewed proposal. I'm using these frameworks as structural tools — ways of formalizing relationships between the empirical findings — not as settled science. The convergence evidence and its predictions don't depend on any one of them being right.
- I am not ignoring the quantitative limitations. Brain-model alignment scores are trending in the right direction but remain modest. Vec2vec translation works better within architectural families than across them. The absolute metrics don't yet demonstrate full geometric identity. This is a framework in its early stages, not a proven theory.
Part 11: The Experiments That Would Test This
The real value of a theoretical framework is whether it generates predictions that can be tested. Here are the ones I think matter most:
- Map the trajectory of creative ideation in embedding space. Put people in an fMRI scanner, have them work on an open-ended creative task, and track how their brain states move through shared embedding space over time. If the Progressive Collapse Framework is right, you should see trajectories starting in high-entropy regions and converging toward low-entropy regions, with the geometry of the high-entropy states aligning better with embedding space structure than the final collapsed states.
- Test whether creative insight corresponds to geometric discontinuity. "Aha!" moments should look like sudden jumps to distant neighbourhoods in embedding space, followed by a new convergence trajectory. Routine problem-solving should show smooth, local trajectories. This is a distinguishing prediction.
- Attempt brain-to-model vec2vec translation without paired data. We can already translate between different human brains without shared stimuli, and between different AI models without paired examples. Can we translate between a human brain and an AI model using only the internal geometric structure of each? If yes, that's among the strongest possible evidence that both are instantiating the same universal geometry.
- Test the layered convergence prediction. Hoffman's Interface Theory predicts that brain-model alignment should be systematically stronger at abstract semantic levels and weaker at perceptual levels. While current evidence is consistent with this, the specific prediction — that the gradient tracks the degree of evolutionary fitness pressure at each processing level — hasn't been tested directly.
- Compare concept space geometry across neurodivergent populations. The framework predicts that autistic, ADHD, and neurotypical individuals share the same concept space geometry but differ in their starting positions and trajectory patterns. This distinguishes "different navigation of the same space" from "different spaces entirely."
- Test prompt specificity optimality. For human-AI collaborative ideation, there should be a measurable optimum of prompt specificity that maximizes output quality — neither too vague (can't locate the right neighbourhood) nor too precise (neighbourhood too narrow for exploration). The optimum should shift with task type: convergent tasks favour precise prompts, divergent tasks favour broad semantic triangulation.
Part 12: Why Now?
I want to close with a note about timing and convergence.
The empirical machinery to test this framework largely already exists. Brain-model alignment is a booming field. Cross-subject shared representations have been demonstrated. Tools for mapping concept space geometry in both brains and models are mature. Vec2vec translation works. Levin's morphospace program is generating experimental results. Wolfram's Physics Project is producing formal structures that can be connected to the empirical findings.
What's been missing is someone connecting the pieces under a specific theoretical question: Is the progressive collapse through a universal geometry the fundamental computational operation performed by any sufficiently capable information-processing system?
Michael Levin's Symposium on the Platonic Space is, I think, a sign that this connection is being recognized. The symposium brings together the AI researchers, neuroscientists, biologists, and philosophers who hold the different pieces. Karl Friston presenting on "The (Platonic) Nature of Things." Rishi Jha and Jack Morris — the vec2vec authors — on "Universal Embeddings." Iain McGilchrist on "Spherical Causation." Denis Noble on "Mathematics Justifies Metaphysics in Biology." The question is now explicitly on the table.
And Wolfram, writing just this month, is asking the same question from the foundations of physics: what is the relationship between observers, computation, and the structure of reality? His estimate that human concepts span 10⁻⁶⁰⁰ of the computational structure of the ruliad should give us pause — and excitement. We're not just navigating a space. We're navigating a space that is almost inconceivably larger than the territory we've mapped. Every new concept we form is a small expansion of our footprint in the ruliad. Every act of creative ideation is a tiny expedition into adjacent possibility.
I don't know if the framework I've described here is correct. But I know it's testable, which makes it scientific rather than philosophical speculation. And if it is correct — if creative thinking, machine learning, neural representation, biological morphogenesis, and the computational structure of reality itself really are all aspects of the same geometric structure — then we're looking at something like a periodic table of meaning: a structured space whose properties we can map, whose neighbourhoods we can explore, and whose attractors we can predict.
The ancients called it the world of Forms. The AI researchers call it the Platonic representation. The biologists call it morphospace. The cognitive scientists call it concept space. Wolfram calls it the ruliad. The mathematicians just call it structure.
Maybe they're all talking about the same place. And maybe the fact that so many different kinds of thinkers keep arriving at the same destination is itself the strongest evidence that the destination is real.
Further Reading
The key sources I draw on throughout this essay:
- Huh, M., Cheung, B., Wang, T., & Isola, P. (2024). The Platonic Representation Hypothesis. ICML 2024.
- Jha, R., Zhang, C., Shmatikov, V., & Morris, J. X. (2025). Harnessing the Universal Geometry of Embeddings. arXiv preprint.
- Levin, M. (2024). Platonic space: where cognitive and morphological patterns come from (besides genetics and environment).
- Wolfram, S. (2021). The Concept of the Ruliad.
- Wolfram, S. (2023). Observer Theory.
- Wolfram, S. (2026). What Ultimately Is There? Metaphysics and the Ruliad.
- Hoffman, D. D., Singh, M., & Prakash, C. (2015). The Interface Theory of Perception. Psychonomic Bulletin & Review.
- Prakash, C., Stephens, K. D., Hoffman, D. D., Singh, M., & Fields, C. (2020). Fitness Beats Truth in the Evolution of Perception. Acta Biotheoretica.
- Barenholtz, E. (2025). The Autoregressive Brain — a new framework for cognition, memory, and language.
- Friston, K. (2010). The free-energy principle: A unified brain theory? Nature Reviews Neuroscience.
- Schrimpf, M., et al. (2021). The neural architecture of language: Integrative modeling converges on predictive processing. PNAS.
- Dodig-Crnkovic, G. (2025). Platonic Space as Cognitive Construct: Toward a Framework of Cognitive Platonism/Platonic Cognition.
- Levin & Hazan (Organizers). (2025). Symposium on the Platonic Space.