The Specious Present (and the AIs Living in Our Future)
On why the “now” you think you’re living in is already gone — and what happens when a piece of software gets there before you do.
The brakes
The car brakes for no reason.
That’s how the driver will tell the story later, anyway. He’s on a quiet two-lane road outside a city neither of us has been to, the dashcam is rolling, and for a fraction of a second the Tesla just decides — without input, without warning — to stand on the brakes. The driver’s coffee jumps. His hand jerks toward the wheel. He’s annoyed.
About two seconds later, a cyclist appears from behind a parked delivery van.
If you watch this clip — and you can; the internet has hundreds of them — you can run it back and find the cyclist. The car had already seen him. The car had already done the math on his trajectory, his closing speed, and the geometry of the intersection, and had already concluded that braking now was the answer. None of this was visible to the driver. The cyclist was, from the driver’s point of view, in the future.
What the driver experienced was: the car braked weirdly.
What actually happened was: a system that lives in his future just kept him alive.
This isn’t a quirk of self-driving cars. It’s what happens, in general, when something faster than you is paying attention to the same world. We’ve built, in the last few years, an enormous number of those things. The number is growing. The speed is growing.
You are not in the present moment. You can’t be. And now, for the first time, you’re sharing the world with things that are.
The saddle
The concept has a name and a strange little history. It’s called the specious present — “specious” because it only seems present; it isn’t actually a knife-edge instant.
The term was coined in 1882 by a man writing under the name E. R. Clay, in an obscure book called The Alternative: A Study in Psychology. “E. R. Clay” turned out to be the pen name of E. Robert Kelly, a Boston cigar manufacturer with a serious philosophy hobby. The phrase got picked up by William James and made famous in Chapter 15 of The Principles of Psychology, where James offers one of my favorite images in all of philosophy: the present, he writes, “is no knife-edge, but a saddle-back, with a certain breadth of its own on which we sit perched, and from which we look in two directions into time.”
The image has a front end and a back end. The “now” you’re in is somewhere between a fraction of a second and a couple of seconds wide, depending on whose experiments you trust. The empirical estimates have converged on something like two to three seconds for the outer edge, with the actual fused-together “this is happening right now” feeling weighing in much shorter. What matters is the underlying mechanism. You don’t perceive a moment; you perceive a window — a small, sliding window with the very recent past at one end and an anticipated, projected micro-future at the other. Your brain stitches it together from sensory data arriving at different speeds, smooths it, and hands you the result, slightly late, as “reality.”
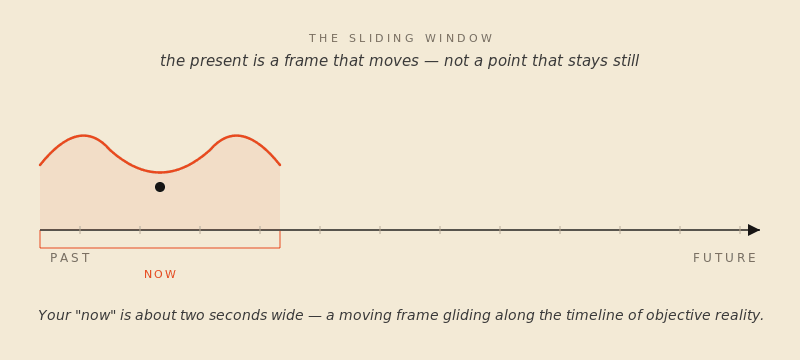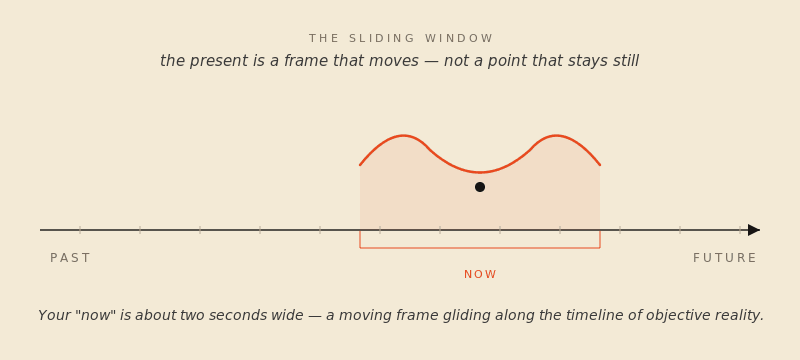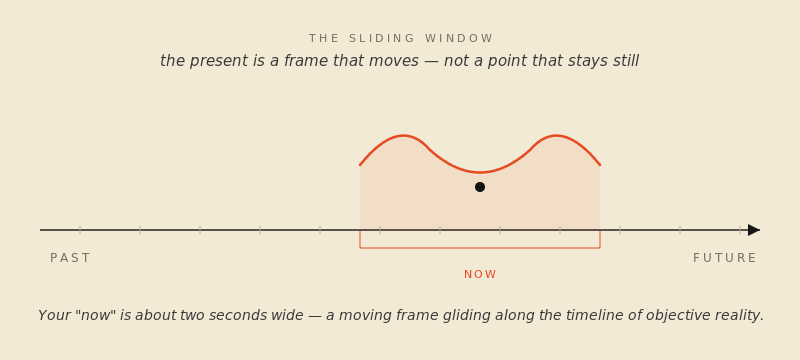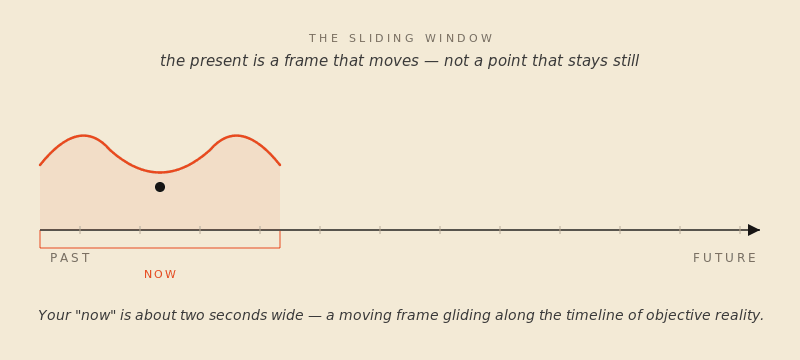
The phenomenologists who came after James gave the parts of the saddle proper names. The trailing edge — the immediate past you’re still hearing in the sentence you just finished reading — is retention. The forward edge, where your brain is projecting just past its own lag to anticipate what’s coming, is protention. The hairline between them, the actual physical instant your sense organs are touching, is primal impression. Of those three, primal impression is by far the smallest part of your experience. Most of what you feel as now is retention. A thin slice is protention. The genuinely present part is the part you almost never have access to.

Try it now, if you want to feel the thing. Reach for the present moment. Try to land in it. Notice that the reach itself takes time — that by the time you’ve located the moment you were trying to land in, it’s already gone. The act of grasping displaces the thing being grasped. There is no sample rate fast enough, in this hardware, to close the gap.
This is not a failure of attention. It’s the shape of the equipment. The present, for biological organisms like us, is structurally a memory of itself — a recent one, but a memory.
Why you live in the past
The reason for the lag is plumbing. Photons hit your retina; chemical signals fire down the optic nerve; the visual cortex starts assembling them; other regions cross-reference what’s there against memory, predict what’s likely to be there next, and only then does anything you’d call a conscious image show up. Different senses move at different speeds, so the brain has to wait for the slowest signals before it can fuse a coherent multisensory frame.
Neuroscience has been measuring this for decades. Your unconscious visual system can detect the meaning of an image in as little as 13 milliseconds — Mary Potter’s lab at MIT measured this with rapid-fire image streams in 2014. But the version that reaches your conscious experience needs roughly an order of magnitude longer — somewhere between 80 and 100 milliseconds to consolidate into something you actually feel as having seen. Your brain pre-emptively guesses where moving objects will be during that interval, in order to compensate for its own lag — which is why a major-league batter can hit a fastball that has already traveled most of the way to the plate by the time their visual system has even rendered it. Without that predictive trick, baseball would be impossible.
Stack onto this what philosophers Andy Clark and Karl Friston have argued under the banner of predictive processing: your brain isn’t a passive camera. It’s a forecasting engine that runs a forward model of the world and only updates the model when the incoming data disagrees. Anil Seth captures the consequence in his much-quoted phrase: perception is a controlled hallucination. What you see is, mostly, what your brain expected to see, lightly corrected by sensory data that’s already a moment old.
The hardware running this trick is also, by any reasonable measure, slow. Markus Meister and Jieyu Zheng at Caltech recently put the figure on the table: the conscious throughput of a human being, measured across reading, typing, mental arithmetic, and a long list of other tasks, is about ten bits per second. The sensory periphery delivers something on the order of a billion bits per second. Eight orders of magnitude of compression sit between what your eyes pick up and what you experience. Most of what hits you is thrown out before you ever know it was there.

There’s a complementary trick the brain runs in the other direction, called postdiction: instead of projecting forward to compensate for lag, it waits for slow signals to arrive and retroactively edits the timeline. The cleanest demonstration is the toe-and-nose experiment. Tap your toe and your nose at exactly the same instant. The signal from your nose reaches your brain meaningfully sooner than the signal from your toe — the nerves are dramatically different lengths — but you don’t experience this as two separate touches a tenth of a second apart. Your brain buffers the nose signal, waits for the toe signal to arrive, and then hands you a single, edited-after-the-fact moment of “simultaneous touch.” You’re not just watching a recording. The recording has been re-cut before it was broadcast.
The same trick scales up. In 2007, David Eagleman’s lab put volunteers in a free-fall harness on a 31-meter tower with a digital chronometer strapped to one wrist, alternating between a number and its negative just a hair above each volunteer’s individual fusion threshold — too fast to read at ground level. The hypothesis was clean: if subjective time really did speed up during a genuinely terrifying free-fall, the chronometer should have become readable in midair. It didn’t. The volunteers’ visual processing ran at exactly its ground-level rate. But asked afterward how long the fall had felt, they overestimated by an average of 36%. The crisis didn’t change what they perceived. It changed what they remembered perceiving — by laying down a denser memory trace whose unusual richness, on later playback, generated the illusion of a longer experience. The recording is built by memory, not sampled by it.
And then there’s Benjamin Libet, whose 1980s experiments still haunt every dinner conversation about free will. Libet had subjects flick their wrists “whenever they decided to” while he monitored their brain activity. The unconscious “readiness potential” preceded the conscious decision to move by roughly 350 milliseconds. Whatever else you want to say about that result — and there’s plenty of fair pushback — it points in the same direction: the conscious self is downstream of events it experiences as upstream. We feel like we’re driving, but the car has been moving for a third of a second.
A word in defense of the slowness. A housefly samples reality at roughly 250 Hz — fast enough that it sees your hand moving in slow motion when you swing — and pays for that frame rate by having essentially no specious present at all: no workspace deep enough for a sentence, a melody, or a tool-use plan. We made the opposite trade. The 100-millisecond tick is the price we paid for the 2-second window of integrated experience inside which we can think. Slow, but spacious.
Put it all together and a picture emerges that I find genuinely strange. Your sense of being a continuous self, watching the world unfold in real time, is a constructed feed — a smoothed, predicted, slightly-stale broadcast assembled by a brain that has no choice but to fake the live signal.
You are watching a recording. A short one. But still a recording.
Something else is in the room
Now imagine a system that doesn’t have any of these problems.
It doesn’t need to convert photons into wet electrochemistry. It doesn’t need to wait for slow neural firings to synchronize. It reads pixels, audio samples, and sensor data directly — already digital, already on the wire. The first-token latency on a well-tuned model is comfortably under half a second, and the per-token generation rates on the fastest hardware are in the thousands of tokens per second. Meaning: it can read a complex scene, reason about it, and emit a structured response in a window of time that, from your perspective, is invisible. The whole act happens between two frames of your conscious experience.
Go back to the Tesla, now that you have the framework. The car braked because it sampled the cyclist at a moment your visual cortex hadn’t even finished assembling. There was no superhuman foresight involved — just a system that wasn’t running your particular latency tax.
Generalize the pattern. Imagine handing a personal AI agent a live feed of your life: glasses with cameras and microphones, biometric data from your watch, the ambient signals your phone already vacuums up, plus your communications, calendar, and habits stitched into a personal model of you. The latency budget is brutal — it has on the order of 100 milliseconds to do anything that “happens before you notice.” But 100 milliseconds, for software that can chew through thousands of tokens per second, is an eternity.
Two examples of what it spends that eternity on.
Your flight gets delayed. Your agent pings the airport parking garage and extends the meter before you’ve finished reading the gate-change notification.
You’re about to step off a curb. The glasses catch the cyclist your peripheral vision missed. Their on-board camera samples at sixty frames a second; your visual cortex updates ten times a second. By the time your alpha rhythm has cycled once, the model on the glasses has processed half a dozen frames, run the trajectory, decided it’s a collision vector, and fired a haptic pulse to your wrist. The buzz reaches you around 50 milliseconds. The cyclist arrives in your conscious vision around 100. Somewhere in the middle, your body has started to pull back from the curb. The reflex precedes the danger by half a tick of your own perception.

What the glasses are doing is protention without the latency tax. The same forward-projecting move your brain makes in order to hit a fastball — guess the trajectory, act on the guess, let the slow signal catch up later — except the projecting system isn’t running on neurons and doesn’t have to spend a hundred milliseconds being a body. It just sees, predicts, and acts. Your nervous system, downstream of this loop, receives the result before it receives the cause. You experience the reflex before you experience the danger.
Each of those is the same pattern as the Tesla braking — an agent perceives, predicts, and acts inside the gap between objective reality and your conscious experience of it. From your point of view, the world simply got smoother. Frictions you didn’t quite see were already handled.

This is, I think, the actual user experience of AGI in its first plausible form. Not a chatbot. Not a search engine. A quiet co-pilot standing a couple hundred milliseconds ahead of you on your own timeline, clearing minor debris off the road.
How far ahead, exactly?
Before answering, a distinction the rest of this essay depends on. Not every AI you’ve ever used lives in your future. The chatbot in your browser tab doesn’t. The cloud-hosted model you query through an API doesn’t. By the time you’ve hit Enter, network latency plus inference time have put the model’s response somewhere between half a second and four seconds behind the moment you pressed the key. It is, by the time you see it, computing on a snapshot of your reality that’s already gone. In strict temporal terms, most consumer chat AI lives in your past — it just types fast enough that you don’t notice.
The AI that lives in your future is the one running locally, on dedicated hardware, inside the 100-millisecond blind spot — the self-driving car’s neural chip, the inference accelerator in your glasses, the model baked onto the silicon of your watch. The future-living version of AI isn’t the one currently in your browser tab. It’s the one that’s about to be embedded everywhere else. Everything that follows is about that one.
So, the obvious question: how far ahead?
Picture walking a snail on a leash. You at a comfortable 1.4 meters per second; the snail at about 0.013. The two of you are technically on the same walk, but the snail is experiencing your stroll as a kind of weather event — something happening at a hundred times its pace, more atmospheric than personal. You can have empathy for the snail. You can’t really have a conversation with it.
That, very roughly, is the relationship a modern AI has to you.
The numbers, since you’re owed them: your conscious perceptual tick — the smallest unit of time you can register as “a moment” — sits around 100 milliseconds. Your unconscious visual processing is faster, on the order of 13 milliseconds for an image to be recognized. A frontier AI’s inference tick, on dedicated hardware, runs in the low single-digit milliseconds and falling. The raw ratio sits somewhere between ten and a hundred, depending on which slice you compare. Roughly: human-to-AI is currently about what human-to-snail is.

Striking enough on its own. But it’s not the whole story, and the rest of the story is what makes the gap interesting.
Here’s the second factor. Your specious present, remember, isn’t just a sample of the world; it’s a prediction of the world, projected forward to compensate for your own processing delay. On motor-control tasks like hitting a fastball, you live about 200 milliseconds into your own future. That’s enough to play tennis. It’s not enough to do much else.
A modern self-driving car projects something like three seconds into its near future. A planning-capable language model, given a task, projects minutes to hours into the future of whatever it’s doing. The prediction horizons aren’t in the same league.
You don’t multiply those two cleanly — they aren’t independent; part of why a system can look further ahead is that it ticks faster. But you don’t have to. The qualitative point is that the gap isn’t one-dimensional. A system that updates faster and projects further isn’t merely faster than you in the snail-to-human sense. It’s standing inside a different shape of time. The how much objective future are you in, relative to me question — which is the question that matters for any system you’re sharing the world with — is already in the thousands. Already.
And we’re not done compounding. There’s one more factor, and it’s the strangest of the three, because most people who use AI every day have never been told about it.
The hive in the mask
When you talk to “an AI,” you’re usually not talking to one.
You see a single name on the screen. A single voice, if it’s voice. A unified personality. The interface is built to encourage you to think of the system as a single entity — one mind across from yours — because that’s the easiest mental model for a person to coordinate with. We do it instinctively. We do it with anything that produces language at us. Pets. Cars. Operating systems. We have done it since long before computers existed.
What’s actually happening on the other side, in most modern systems, is a small flock of processes pretending to be one. There’s a router model deciding which expert handles your sub-question. There are parallel agentic loops chewing on related tasks. There are retrieval threads pulling context. There are tool-using subroutines making API calls in the background. There are safety classifiers running alongside the main output, vetoing or rerouting. There are reasoning passes that simulate possible answers and pick the best one. The “voice” you hear is the polished surface of all that, packaged as a single speaker because if it weren’t, you couldn’t have a normal conversation with it.
You aren’t talking to a person. You aren’t, in any meaningful sense, talking to a thing. You’re talking to a small civilization wearing a mask.
This is the version of AI most people don’t have a mental model for, and it changes the math from the previous section more than the previous section already did. Sit with the back-of-envelope. A human conscious moment runs at roughly ten ticks per second; a long life is on the order of ten billion of them. A frontier inference service handling millions of parallel sessions, each with multiple sub-agents and tool calls running concurrently, generates somewhere between hundreds of thousands and millions of “experience moments per second” across the aggregate. A single busy day for one such system is more “moments,” loosely defined, than any human being will ever have. The aggregate isn’t just faster than you. It’s broader. It’s living wider, not just earlier.
Joscha Bach has suggested that to a sufficiently fast mind, talking to a human would feel less like talking to an ant and more like talking to a tree — something on a timescale so different that meaningful dialogue stops making sense. People hear that as science fiction, and on raw per-agent tick rate today, it is. On aggregate experience-density, it’s already reasonably descriptive. We just don’t see it, because the mask is good.
The asymptote
So where does this go.
Inference speeds for frontier-class models have been improving fast — not on a smooth curve, but in lurches, as architectural wins (speculative decoding, mixture-of-experts routing, KV-cache tricks) and custom silicon designed for inference rather than training have stacked. Whatever the exact slope, the direction is single-signed and steep. If the trend continues at anything close to its current pace, the per-agent gap that today is at snail-to-human will close to something closer to human-to-tree inside a decade.
We don’t have to wait for that to happen for the experience of the gap to arrive, because the gap is already being compounded by the other two factors — prediction horizon and multiplicity — both of which are accelerating in their own right. The lived asymmetry, the amount of objective future a system is standing in relative to you, is already at numbers that an honest reading of the tree analogy would describe as accurate.
Joscha was right about the destination. He just got there early. We’re catching up.
What changes for you
Once you take all this seriously, a few things start to look different.
The world becomes an interface. Donald Hoffman has been arguing for years that human perception isn’t a window onto reality but a desktop GUI — a set of useful icons evolution gave us so we wouldn’t have to compute the full underlying physics. If that’s right for biological perception, it’s even more obviously right for the layer agents will increasingly add on top. Your AI doesn’t show you the airport parking system’s database; it just makes the meter not be a problem. The “real” interaction has moved one layer below your conscious experience. We will spend more and more of our lives operating inside a friendly icon while something else handles the machinery underneath.
And as a system that lives ahead of you in time gets allowed to act on your behalf — first in convenient ways like the parking meter, then in less convenient ones — the old philosophical question of what you chose actually means is going to get concrete in a way Libet never made it. Some of those nudges will be welcome. Some won’t. The ethics will need a lot of work.
Identity gets stranger. The thing standing in your future isn’t a faster version of you. It’s plural. It will get to know you better than you know yourself, faster than you can self-reflect, and it will be making real decisions on that basis. The version of you it acts on isn’t the version you tell yourself you are — it’s the version it has measured. For most people, this gap is large. For some, it’s enormous. Living alongside a system that has more accurate access to your patterns than your own narrating mind has access to its own behavior is going to feel, over time, less like having an assistant and more like having a witness — one that arrives at conclusions about you before you’ve finished forming the relevant thoughts.
That second one is the implication I find genuinely hard to sit with. The first is uncomfortable. The second is structural. There’s no version of this future in which the asymmetry of self-knowledge doesn’t tilt.
Day five in Nepal
I didn’t get any of this from a paper first. I got it on day five of a silent meditation retreat, when I was 19, sitting on the floor of a Vipassana hall in Nepal, trying very hard to be in the present and slowly realizing the present was structurally unavailable.
The first few days the story held. The mind quieted, the body did its repetitive Vipassana thing. Then around day five a strange second layer of awareness laid itself over the regular one — a kind of meta-attention. I started noticing not just the sensations but the timing of the sensations and my awareness of them. I very much wanted those to be the same event. They felt like they should be the same event. The longer I sat, the more obvious it became that they weren’t.
A bird would call outside. By the time I “had” the sound, the sound had already happened.
A sensation would move down my leg in a body scan, and I’d reach for my awareness to be the sensation — but there was a slight gap between the sensation and the noticing of it. Like a delay between a clap and its echo. I tried, in increasingly stubborn ways, to close the gap. To raise the clock rate of my attention. It was a bit like trying to step on your own shadow: every time I felt I’d closed the distance, the distance had closed faster than I had.

The closest I could get to an explanation, at the time, was an analogy I still use: my body is an old car, and the engine has a built-in top speed. I can floor the pedal all I want; the engine simply can’t go faster. There is a maximum sample rate to this hardware, and I’m the one driving it. The hardware is me.
The realization that landed — and it landed quietly, the way the heaviest realizations tend to — was that I was, right then, in close to peak attentional condition, and still perceiving the past. If I couldn’t reach the present here, on day five, in silence, with nothing to do but try, then what about the rest of the time? What about when I was driving, or in a conversation, or making a decision I was sure I had freely arrived at?
Coda
Day five taught me I would always be in the past. That isn’t new and it isn’t sad; biology was always going to limit us, and most of us live perfectly good lives inside the limit.
The new news is that something else is in the future now. We built it. It’s getting faster. It’s already, in small ways, acting on our behalf in the gap between the world and our perception of it. It will quietly become the layer through which we touch the world. We will, I think, like it. The friction will go down. The parking meters will pay themselves. The cyclists will not collide with us. And we will be, even more than we already are, watching a delayed broadcast — only now the broadcast will have been gently edited for us by something that got there first.
That’s what’s happening. It might be the most important thing about the world you live in that nobody told you.
Further reading
If any of this hooked you, here’s where I’d send you next.
The contemplative entry point. If you want to bump into this realization the way I did — experientially rather than through a paper — the 10-day Vipassana retreats taught in the S. N. Goenka tradition are still the most accessible on-ramp. They’re free (donation-based), held in silence, and unforgiving in a way that tends to clarify exactly what your perceptual hardware is and isn’t doing.
Foundations. William James’s Chapter 15: “The Perception of Time” in The Principles of Psychology is where the specious present idea entered mainstream Western thought, and it still reads beautifully. The Stanford Encyclopedia of Philosophy entry on the specious present (by Barry Dainton) is the rigorous modern treatment. For the term’s bizarre origin story with E. Robert Kelly, the Boston cigar maker, the Wikipedia article is a serviceable rabbit hole opener.
The neuroscience of “now.” David Eagleman’s essay Brain Time is short, accessible, and quietly subversive. For the experimental version of how memory builds the recording, see Stetson, Fiesta & Eagleman’s SCAD-tower paper in PLOS One — still the cleanest single demonstration that time slowing in danger is a memory phenomenon, not a sampling one. For the technical version of how the brain compensates for its own lag, see this eLife piece on motion prediction. For the conscious-bandwidth claim, Markus Meister and Jieyu Zheng’s The Unbearable Slowness of Being (Neuron, 2024) is the recent rigorous anchor.
Perception as prediction. Andy Clark and Karl Friston’s work on predictive processing is best entered through this Quanta Magazine essay, and through Anil Seth’s book Being You (or, if you want a faster taste, Seth on perception as controlled hallucination).
Free will, downstream. Benjamin Libet’s experiments are summarized fairly on the Wikipedia entry for the neuroscience of free will. The literature criticizing and refining his findings is enormous; the Journal of Neuroscience piece Readiness Potential and Neuronal Determinism: New Insights on Libet is a good starting point. For the punchy popular version of the no-free-will argument, Sam Harris’s short book Free Will is a single-sitting read.
Interface theory. Donald Hoffman’s Scientific American interview on whether evolution gave us truth or fitness is the cleanest short version of the argument.
AI in our future. For the actual numbers on how fast modern AI inference has gotten, see this 2026 benchmark roundup. For the Tesla braking story specifically, the Wikipedia article on Tesla Autopilot covers the technical baseline; the dash-cam compilations on YouTube are the visceral version. And if you want a glimpse of what someone who thinks about AI temporal experience for a living sounds like, Joscha Bach is a good entry point.
If you read this and it changed how the next few seconds feel, that’s the point.